RAG 최적화의 어려움을 개선하기 위한 방법
- 검색 결과의 질을 높이기 위해 리랭커 추가
- 다양한 프롬프팅 전략을 도입하여 답변의 질을 높인다.
- 벡터 검색 방식을 최적화한다.
=> 성능 개선을 위해 여러 기능이 추가된 것을 Advanced RAG
=> 어느 조합이 최선인지 아무도 알 수 없음 [ 검색하는 문서의 종류, 사용자 쿼리 특성, 서비스 목적 ]
=> Auto RAG : RAG 최적화 자동화 도구 [ 다양한 파라미터가 정의된 yaml 파일을 기반으로 여러 가지 조합을 자동으로 실험하고 최적의 조합을 찾아주는 툴
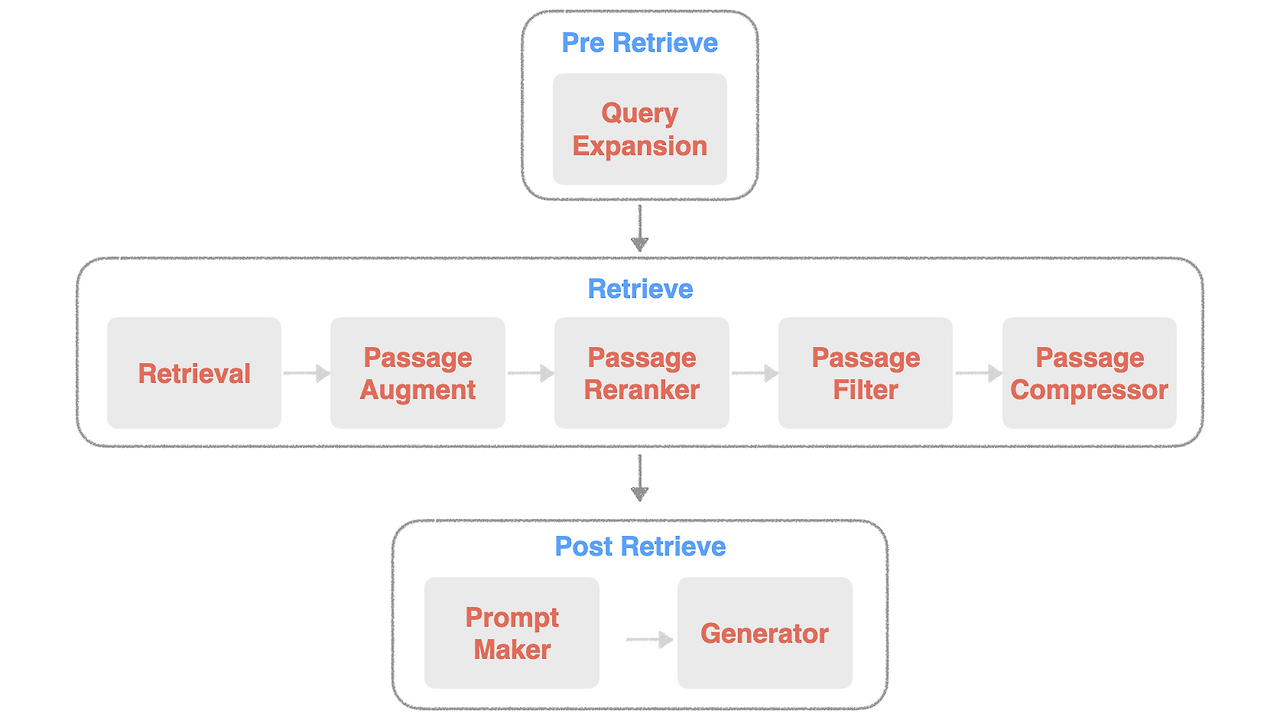
주요 단계를 노드로 표현하고, 각 노드 별로 적용할 수 있는 실험 요소들을 모듈로 나누어 관리
전처리 단계인 pre retrieve와 검색 단계인 Retrieve, 검색 이후의 Post Retrieve
1. Query Expansion :

사용자 질문을 바로 검색 활용 대신 해당 질문을 LLM을 통해 보다 구체적으로 확장하는 방식
확장방식은 Query Decomposition, HYDE, Multi Query Expansion 등 이 존재
쿼리를 더 정교하게 만들고 풍부하게 만들
어 검색 성능이 향상될 수 있음
2. Retrieval :

query를 바탕으로 관련 문서의 단락을 찾는 단계. BM25와 같은 키워드 기반 검색과 VectorDB를 활용한 의미론적 검색 모두 지원하며 두 가지 방식을 결합한 Hybrid방식도 사용 가능 (개인적으로 한국어 문서에 대해 hybrid 방식이 좋음)
평가지표로는 f1-score, precision,recall,ndcg,mrr,map 등이 사용
3. Passage Augmenter :

검색된 단락을 그대로 활용하는 대신 해당 단락의 앞뒤 내용을 추가로 가져오는 방법. 검색된 단락만 활용하는 것이 아닌 주위 문맥을 함께 가져오는 방식으로 풍부한 자료를 가지고 답변 생성
4. Passage Reranker

- 검색된 문서 단락들을 보다 정교하게 재정렬하는 단계. 검색 자체도 중요하지만 더욱 의미 있는 순서로 결과를 재정렬
- 검색된 문서들을 LLM에게 제공할 때, 중간에 위치하는 정보는 LLM이 잘 파악하지 못하는 경향이 있음 => 이를 lost in middle
- 질문과 관련된 문서일수록, 상위에 존재해야 함 (AWS 기술 블로그 기술)
=>
- 임베딩 벡터 변환은 문서를 N개의 숫자로 재 표현하는 것을 의미하는데 첫번째는 문서가 긴 경우 정해진 벡터의 차원으로 표현하기 어려울 때 발생
- RAG는 검색 시간 단축을 위해 Anns(approximate Nearest 기술을 활용하는데 이 방법은 질문과 문서 사이의 관련성 체크 횟수를 줄임으로써 검색 속도를 높일 수 있음 => 하지만 이 방식은 관련성 정확도 하락이 정보 손실이 발생
[1] Lost in the Middle: How Language Models Use Long Contexts, F.Liu et al., 2023
=> 이 논문에 따르면 RAG의 정확도는 관련 정보의 컨텍스트 내 존재 유무가 아닌, 순서로 관련 정보가 컨텍스트 내 상위권에 위치하고 있을 때 좋은 답변을 얻을 수 있음

Reranker는 질문과 문서 사이 유사도 측정을 목표로 함
이는 기존의 벡터 검색의 목적과 동일하지만 독립 임베딩을 활용하는 Bi-encoder형태의 벡터 검색과는 다르게 Rerank는 질문과 문서를 하나의 input으로 활용하는 cross-encoder형태를 사용함
Rerank는 질문과 문서를 동시에 분석함으로써 더욱 정확한 유사도 측정이 가능
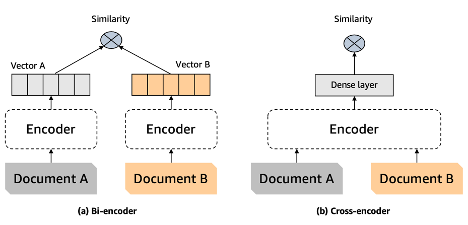
여기서 rerank가 임베딩 모델을 대체할 수 도 있다고 생각할 수 있지만 질문과 문서를 동시에 인풋으로 활용하는 reranker의 특성 상 사용자가 질문을 하는 시점에서 모든 문서들에 대한 관련성을 측정하여 오래걸릴수밖에 없음
=> Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Reimers et al., 2019 에서는 4천만개 문서에 대해 V100 GPU기반으로 연관성 측정을 수행했을 때 약 50시간이 소요 된다고 보고하고 있습니다.

=> 문제점 극복을 위해 two stage를 사용, 첫번째 단계에서는 기존의 벡터 검색 방식으로 대규모 문서 중 질문과 관련성이 높은 후보를 검색하고 2단계에서는 검색 문서들에 대해 rerank 기반으로 관련성을 재측정
=> 첫번째 단계를 통해 검색 속도를 높이면서 두번째 단계에서 질문의 연관성을 측정하여 rerank가 가능하도록 함
5. Passage Filter

검색된 단락 중에서 질문과 관련이 없는 부분을 제거하는 과정입니다. 불필요한 단락이 답변 생성에 포함되면 LLM이 혼란을 겪거나 할루시네이션을 일으킬 수 있어 필터링을 통해 질을 높인다.
6. Passage Compressor

검색된 여러 단락을 LLM에 전달하기 전에 요약하는 단계입니다. 요약을 통해 핵심 정보를 간결하게 전달하면, 더 나은 답변을 기대할 수 있음. 또한 토큰 사용량을 줄임으로 운영 비용과 응답 속도를 개선
7. Prompt Maker

프롬프트 엔지니어링은 원하는 답변을 이끌어내기 위해 매우 중요한 요소입니다. 다양한 프롬프트를 리스트업하고 실험하여 최적의 프롬프트를 찾아나감. Prompt Maker는 그 자체로는 평가가 불가하여 generator의 성능을 통해 간접적으로 평가됨.
8. Generator
답변을 생성하는 LLM 자체를 다양하게 적용하며, 어떤 LLM이 가장 적절한지 실험. 성능 평가 지표로는 bleu,meteor, rouge,sem_score, g_eval, bert_score 등이 사용
AutoRAG는 최적의 구성을 찾기 위해 평가 데이터셋을 활용
평가 데이터는 쿼리와 정답으로 구성되며, 평가 데이터셋을 기반으로 점수를 매겨 각 노드별 최적화가 이루어지도록 함
=>
평가 데이터셋의 중요성 : 도메인 지식을 가진 전문가가 해당 평가 데이터를 전처리하고 관리하는 것이 중요함